This chapter describes some of the techniques the HPF language and the pghpf compiler use to handle data distribution among processors on a parallel system. This chapter also describes some data distribution limitations for the current version of pghpf. The pghpf compiler distributes data and generates necessary communications with the assistance of the pghpf runtime library. Depending on the data type, distribution specification, and alignment specification, as well as each computation's required data access, data is communicated for a particular expression involving some computation. Data distribution is based on the data layout specified in the HPF program, the design of the parallel computer system and the layout and number of processors used. Some mapping of data to processors is specified by the programmer, other mapping is determined by the compiler.
The pghpf runtime library takes into account the communications to be performed and is optimized at two levels, the transport independent level where efficient communications are generated based on the type and pattern of data access for computations, and at the transport dependent level where the runtime library's communication is performed using a communications mechanism and the system's hardware. To generate efficient code, data locality, parallelism, and communications must be managed by the compiler. This chapter describes the principles of data distribution that HPF and the pghpf compiler use; the HPF programmer needs to be aware of some details of data distribution to generate efficient parallel code.
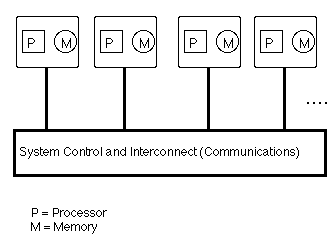
Figure 5-1 A Distributed Memory Parallel System
! distribution directives not supplied - replication PROG1 INTEGER BARRAY(100) !default distribution directives supplied - replication PROG2
INTEGER BARRAY(100) !HPF$ DISTRIBUTE BARRAY(*)
Example 5-1 A default distribution
REAL X(15), Y(16) !HPF$ DISTRIBUTE Y(BLOCK) !HPF$ ALIGN X(I) WITH Y(I+1) FORALL(I=1:15) X(I)=Y(I+1)The next example is very similar, but uses a CYCLIC distribution. A cyclic distribution divides data among processors in a round-robin fashion. A block distribution divides data into evenly distributed chunks (as evenly as possible) over the available processors. A cyclic distribution divides data over processors so that each processor gets one element from each group of n elements, where n is the number of processors.
Figure 5-2 shows block and cyclic distributions for a one dimensional array. Depending on the computation performed different data distributions may be advantageous. For this computation a CYCLIC distribution would involve communication for each element computed.
REAL X(15), Y(16) !HPF$ DISTRIBUTE Y(CYCLIC) !HPF$ ALIGN X(I) WITH Y(I+1) FORALL(I=1:15) X(I)=Y(I+1)In the next example, a similar distribution represents a computation that would be partitioned over the available processors, (for the example we call the processors processor one and processor two). Because of the alignment specified in these ALIGN and DISTRIBUTE directives, the computation involves communication since the value for Y(9) when I is 8 needs to be communicated to assign it to X(8). X(8) is stored on processor one and Y(9) is stored on processor two.
REAL X(15), Y(16) !HPF$ DISTRIBUTE Y(BLOCK) !HPF$ ALIGN X(I) WITH Y(I) FORALL(I=1:15) X(I)=Y(I+1)The following example shows an erroneous distribution that programmers should avoid. According to the HPF specification, the value of a dummy index variable, I in this example, must be valid for all subscript values possible for the data, X in this example. When the ALIGN dummy index ranges for all possible value of I, 1 to 16 for this example, there would be an invalid access to the value Y(16+1). This error will give a runtime error.
REAL X(16), Y(16) !HPF$ DISTRIBUTE Y(BLOCK) !HPF$ ALIGN X(I) WITH Y(I+1) FORALL(I=1:15) X(I)=Y(I+1)This code produces the following runtime error message :
0: __hpf_setaln: invalid alignment 1: __hpf_setaln: invalid alignmentFor more details on different data distributions and examples showing more HPF data mapping directives, refer to Chapter 4 of The High Performance Fortran Handbook.
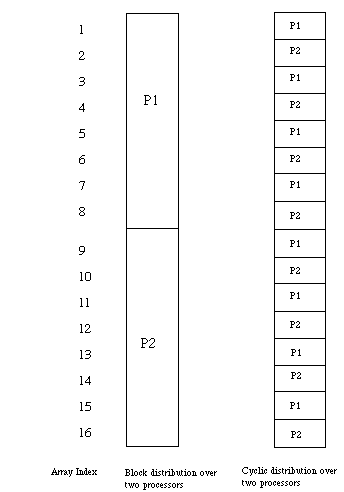
Figure 5-2 Block and Cyclic Distribution
Using allocatable arrays, it is important to keep in mind that an object that is being aligned with another object must exist. Thus, in the following example, the order of the ALLOCATE statements is correct; however, an incorrect ordering, when B is allocated before A, will produce a runtime alignment error.
REAL, ALLOCATABLE:: A(:), B(:)
!HPF$ ALIGN B(I) WITH A(I)
!HPF$ DISTRIBUTE A(BLOCK)
ALLOCATE (A(16))
ALLOCATE (B(16))
The algorithm pghpf uses to determine distribution of temporaries takes the statement in which the temporary is used into account. Temporaries are allocated before the statement in which they are used and deallocated immediately after that statement. For example, an array assignment:
INTEGER DIMENSION(1000):: A,B,C,Dwould generate intermediate code using temporary arrays.
A = SUM(B,DIM=1) + MATMUL(C,D)
For this class of temporaries, distribution is based on the usage of the temporary. If a temporary is used as the argument to an intrinsic, the compiler tries to determine the distribution based on the other intrinsic arguments. Otherwise, it tries to assign a distribution based on the value assigned to the temporary. Otherwise, the temporary is replicated across all processors.
Numerous factors including array alignment, array distribution, array subsection usage and argument usage need to be taken into account in determining temporary distribution. For example, consider the following :
A(1:m:3) = SUM(B(1:n:2,:) + C(:,1:n:4), dim = 2)The section of A is passed directly to the SUM intrinsic to receive the result. A temporary is needed to compute the argument to SUM. The distribution of that temporary has two possibly conflicting goals: minimize communication in the B+C expression, or minimize communication in the SUM computation and in the assignment to A.
The bounds of a FORALL statement are localized according to the array elements owned by the left-hand-side.
For BLOCK partitioned dimensions, the loop bounds are adjusted to index the slice of data owned by the current processor.
For CYCLIC partitioning, two loops are required. The outer loop iterates over the cycles of the data, and the inner loop iterates over the data items in the cycle.